Search engines are powerful tools, yet it is surprisingly simple to provide direction to search engines and ensure that content is shown (and hidden) appropriately in search results. Likewise, it is surprisingly easy to make mistakes and instruct a search engine to show (or hide) content unintentionally. Understanding the basic tools that search engines provide allows website administrators to instruct search robots to ensure that important content appears in search results, and avoid making costly mistakes.
Indexing Methods
Search engines use three basic actions to discover new content to present in search results:
- Crawl
- page content is read by search engines
- Follow
- in-page links are traversed by search engines
- Index
- page is recorded and may appear in search results
Search engines provide content authors with tools to control behavior when new content is discovered: the robots.txt file and the robots tag.
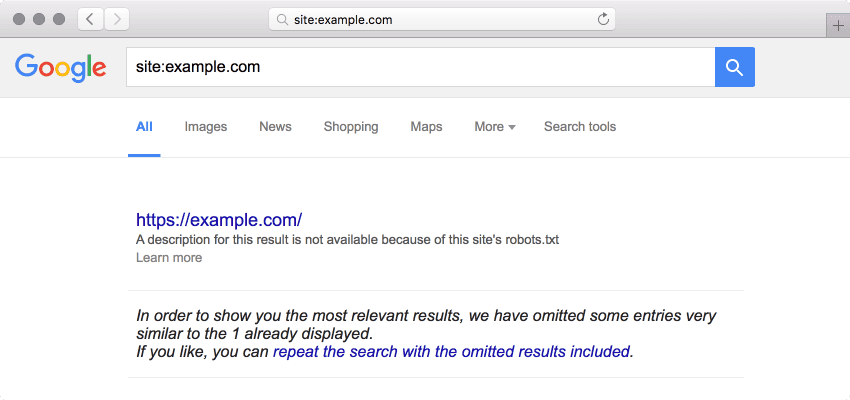
The robots tag controls indexing and following, while the robots.txt file controls crawling (evidence of which can be seen in the Google search results: “A description for this result is not available because of this site’s robots.txt”).
There are a number of directives (described by Google’s robots.txt specification as “guidelines for a crawler or group of crawlers”) that allow content authors to prevent search engines from crawling, following and indexing content; by default, there are no restrictions for crawling; pages are treated as crawlable [and] indexable… unless permission is specifically denied.
The primary directives for restricting search engine behavior are:
disallow- Do not crawl, access (i.e. read content from) the specified paths.
noindex- Do not index this page (i.e do not show in search results).
nofollow- Do not follow (i.e. attempt to crawl) links on the page.
Crawl Directives in robots.txt
The robots.txt is a plain text file accessible at the top-level directory of the host (domain) encoded in UTF-8.
Note: Crawlers will not check for robots.txt files in subdirectories.
In standard UNIX fashion, comments can be included at any location in the file using the “#” character; all remaining characters on that line are treated as a comment and are ignored.
Interestingly, “a maximum file size may be enforced per crawler. Content which exceeds the maximum file size may be ignored. Google currently enforces a size limit of 500 kilobytes”.
The robots.txt file is broken up into sections (called “groups”), each defined/separated by a user-agent record.
Only one group of group-member records is valid for a particular crawler… All other groups of records are ignored by the crawler… The order of the groups within the
robots.txtfile is irrelevant.– Google’s robots.txt specification: Order of precedence for user-agents
Non-human Readable Files
Ensure that search engines can crawl CSS and JavaScript files.
Disallowing crawling of JavaScript or CSS files in your site’s
robots.txtdirectly harms how well our algorithms render and index your content and can result in suboptimal rankings.
If resources like JavaScript or CSS in separate files are blocked (say, with
robots.txt) so that Googlebot can’t retrieve them, our indexing systems won’t be able to see your site like an average user. We recommend allowing Googlebot to retrieve JavaScript and CSS so that your content can be indexed better. This is especially important for mobile websites, where external resources like CSS and JavaScript help our algorithms understand that the pages are optimized for mobile.
Robots Tag
The robots tag may be defined either directly in the HTML as a meta tag:
<meta name="robots" content="noindex, nofollow">
Or in the HTTP X-Robots-Tag header:
X-Robots-Tag: noindex, nofollow
NOTE: A value of none is equivalent to noindex, nofollow.
The quantity and order of robots directives does not matter, if multiple directives exist, the most restrictive directive will be used:
If competing directives are encountered by our crawlers we will use the most restrictive directive we find.
– Robots meta tag and X-Robots-Tag HTTP header specifications
Noindex a Section of a Site
Using the X-Robots-Tag HTTP header, it is possible to prevent search engines from indexing sections of a site, and/or particular file types:
# Prevent indexing of all pages with `/category/` in the URL
RewriteCond %{THE_REQUEST} /category/
RewriteRule ^ - [ENV=NOINDEX:true]
<IfModule mod_headers.c>
Header set X-Robots-Tag "noindex" env=NOINDEX
</IfModule>
# Prevent indexing of image files (.png, .jpeg, .jpg, .gif)
<Files ~ "\.(png|jpe?g|gif)$">
Header set X-Robots-Tag "noindex"
</Files>
Removing Content from Google SERPs
To remove a page from Google’s Search Engine Results Pages (SERPs), a noindex directive may be used, but the disallow directive in the robots.txt file should not be used.
To permanently block a page from Google Search results, take one of the following actions:
- Remove or update the content on your page.
- Add a noindex tag to your page.
Don’t use robots.txt as a way to block your page.
De-indexing Catch 22
As previously noted, when the robots.txt includes a disallow directive for a page, Google will not crawl (i.e. read the contents of) the page. This means that even if the page includes a noindex directive, Google will not be able to find that directive-the noindex directive is never read and the search engine does not know to remove the pages from the index. In such cases, pages which have already been indexed by Google will continue to appear in SERPs – “stuck” in perpetuity.
As Google Search Console’s Remove URLs tool instructs, the best way to de-index the site is to allow the search engine to crawl the site.
robots
metatags andX-Robots-TagHTTP headers are discovered when a URL is crawled. If a page is disallowed from crawling through the robots.txt file, then any information about indexing or serving rules will not be found and will therefore be ignored. If indexing or serving rules must be followed, the URLs containing those rules cannot be disallowed from crawling.– Combining robots.txt rules with indexing and serving rules
Do not use robots.txt as a blocking mechanism.
If you blocked the page before removing your content permanently (step 1), unblock and then reblock the page. This clears the page from the index, if it was recrawled after blocking.
To remove a page from Google’s Search Engine Results Pages (SERPs):
- Add a
noindexHTTP header or meta tag to the pages - Allow search engines to crawl pages by removing the
disallowdirective from therobots.txtfile (if adisallowdirective exists) - Claim the domain (in Google Search Console) and submit the URLs for removal
You can use the Removals tool within Google Search Console to temporarily remove a URL from Google’s index.
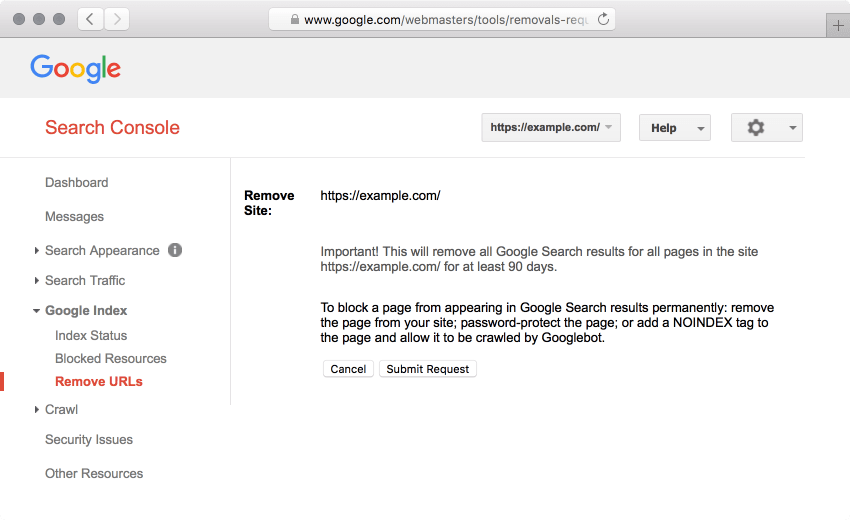
As seen in the screenshot above:
To block a page from appearing in Google Search results permanently… add a NOINDEX tag to the page and allow it to be crawled by Googlebot.
NOTE: To remove all URLs which begin with a specific path, a URL prefix may be used. Using this method, all URLs for a domain may be removed from Google Search results by entering a single forward slash (“/”) into the prompt in Google Search Console’s Remove URLs tool.

Once you’ve successfully removed the URLs from Google Search results, the SERP page should appear empty. The site: search operator may be used (in combination with an inurl: search operator, as needed) in Google search to check if the URLs still appear within Google Search results (e.g. “site:example.com inurl:/path/”).
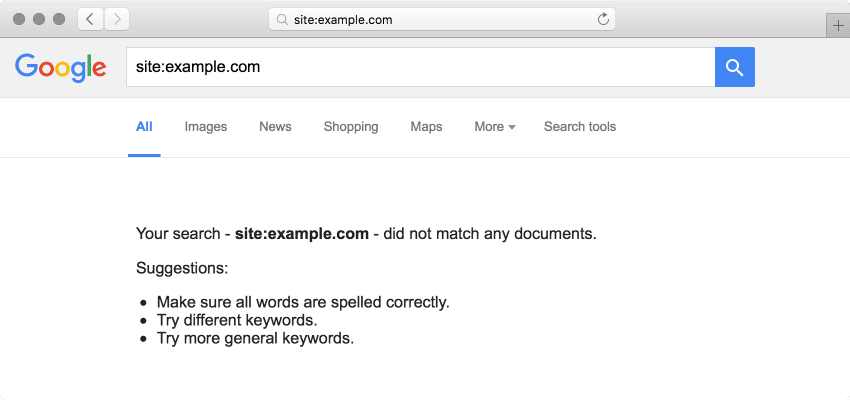
Removing Images from Google SERPs
While Google suggests not using robots.txt as a way to block pages, it turns out that Google treats the robots.txt file differently for images. For images, the robots.txt directive is effective because it provides flexibility and control through the use of wildcards and subpath blocking.
There are two ways to remove images from your site from Google’s search results:
- robots.txt disallow rules.
- The noindex X-Robots-Tag HTTP header.
The two methods have the same effect, choose the method that is more convenient for your site. Keep in mind that Googlebot has to crawl the URLs to extract the HTTP headers, so implementing both methods at the same time doesn’t make sense.
You can instruct Google to exclude any files within an images directory from their index using the following robots.txt declaration:
User-agent: Googlebot-Image
Disallow: /images/
NOTE: In order for a robots.txt directive to take effect, Google must recrawl the site. As such, after implementing a robots.txt directive, it will take some time before an image is removed from search results. For more immediate results, you may use the Google Search Console Removals tool.