Last week I received an email from a client outlining an issue they were encountering with Amazon’s Route 53 health checks which lead to a discovery about how Amazon’s string based health checks operate and how that can create issues with the performance monitoring tool New Relic.
The Incident
I was sitting at my desk when an unsuspecting email appeared in my inbox:
Joey,
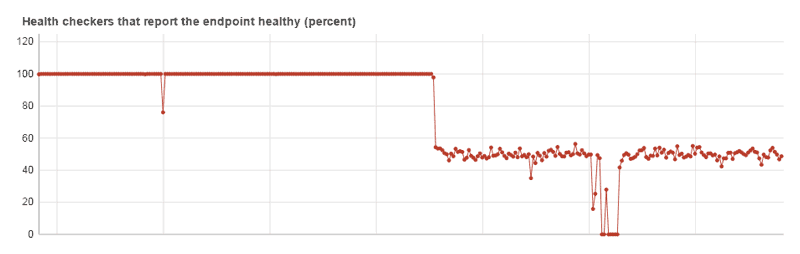
Something changed and Amazon can no longer reliably monitor the site’s health. See the first graph below. This started around 1AM last Friday. Since then you can see that the health percent from each test point is less than 60% and thus we can no longer rely on this to monitor the site. The monitoring used to be perfectly spot on, so something has changed.
I’ve attached a screenshot of the health check configuration. Why this is failing makes no sense, but I’ve tripled checked. Amazon’s test points are whitelisted on the firewall and have no problems resolving the correct load balancer IP address, but for whatever reason it cannot find the [search string] on the main page.
Also attached is a second screenshot of the status of all the most recent checks and their result for reference.
Thanks,
Jeff


The Clues
While I’m not particularly well versed in Amazon’s health check system, I could tell based on the screenshots that the health check was configured to use a search string which is an approach commonly used in other health check systems to ensure that a 200 response isn’t, in fact, a blank page or error page. I knew that I could reproduce this health check myself with the following command:
curl -sL https://www.site.com | grep $search-string
However, running this command multiple times did not reproduce the issue. The search string was found every time.
So I made a cursory search of Google to learn more about Amazon’s Route 53, and found:
[When using] health checks with string matching… The string must appear entirely in the first 5120 bytes of the response body
Ah-ha! So Route 53 has a byte limit restriction on the string matching health check. Armed with that information, I was able to amend the previous manual check, and this time I was able to reproduce the issue.
curl -sL https://www.site.com | head -c 5120 | grep $search-string
Now, I know from experience (and based on Jeff’s email) that this site has two web servers behind a load balancer. Fortunately for me, our server configuration exposes which server responds to a particular request, so I was able to see that while responses from “Web 1” were succeeding, responses from “Web 2” were failing.
Looking at the responses from both servers, it became clear that there was JavaScript at the top of each response that was different between the two servers. In the response from “Web 2” there was more JavaScript. So much JavaScript the the page title (which included the first occurrence of search string on the page) was pushed just beyond Amazon’s 5120 byte limit.
This was concerning; given our automated deployment process, having different code across the two servers should not be possible.
After a moment, I realized that the JavaScript was a requirement of a performance monitoring tool we use: New Relic. …but the question remains, if it wasn’t included in the codebase, why was it different? How did it get on the page?
The Culprit
So I fired up Google again, this time searching for more information on New Relic’s JavaScript, and found New Relic documentation reports “the PHP agent will automatically inject the Browser JavaScript into your pages.”
Great, so now we just need to check which version of New Relic’s PHP agent is installed on each server. As I suspected, the versions across the two server’s are indeed different:
| Server | Agent | Version |
|---|---|---|
| Web 1 | newrelic-php5.x86_64 | 6.5.0.166-1 |
| Web 2 | newrelic-php5.x86_64 | 7.1.0.187-1 |
As it turned out, our hosting provider had upgraded the New Relic Agent while investigating an issue the week prior.
As a temporary solution I suggested checking for another unique string that appear prior to the New Relic JavaScript and was unlikely to appear on a blank page or error page.
Ultimately, I learned that given Route 53’s 5120 byte limit to string matches, it may be difficult to use newer versions of New Relic’s agent along with Route 53 unless modifications are to the header of the document, like adding a unique string very early on in the document.
Case closed.